January 13, 2025 — 10 minutes read
java concurrency
Part 5 in a series of articles about Project Loom.
In this part we re-implement our proxy service using a Reactive Streams API.The companion code repository is at arnaudbos/untangled
If you’d like you could head over to
Part 0 - Rationale
Part 1 - It’s all about Scheduling
Part 2 - Blocking code
Part 3 - Asynchronous code
Part 4 - Non-thread-blocking async I/O
Part 5 - Reactive Streams (this page)

Photo by Sergio Gonzalez on Unsplash
Table Of Contents
Spoiler alert: I have a love-hate relationship with the Reactive Streams specification and implementation libraries.
Let’s see what they have to offer, and what are the tradeoffs.
Reactive Streams
Let me begin with a quote:
Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure. This encompasses efforts aimed at runtime environments (JVM and JavaScript) as well as network protocols.
Two sentences, but a lot to unpack here. Reactive Streams, the concept and the ensuing
specification, is about unifying efforts, across platforms, to provide foundations for
building scalable systems with the following characteristics (which I’ll let you
read the definition of on the Reactive Manifesto): responsive, resilient, elastic
and message driven.
The key takeaways are asynchronous stream processing, non-blocking and back pressure.
We’ll dive into the first two and leave the last one for another post. For the reminder of this article, the “Reactive Streams way” will be illustrated using Pivotal’s Project Reactor.
Reactor is a fourth-generation reactive library, based on the Reactive Streams specification, for building non-blocking applications on the JVM.
The honeymoon
As I said in the previous installment of this series, Reactor is one such library which implements the Reactive Streams specification and provides a “composable, functional, declarative and lazy API".
So let’s see how it can help us turn the gobbledygook of callback nesting,
that was born out of Java NIO, into a simple program. We’ll begin with the
makePulse function.
(makePulse is the function responsible for periodically sending the heartbeat requests in the use-case we’ve already seen throughout this series)
private Mono<Void> makePulse(Connection.Available conn) {
① return Flux.interval(Duration.ofSeconds(2L))
② .flatMap(l -> coordinator.heartbeat(conn.getToken()))
③ .doOnNext(c -> println("Pulse!"))
④ .then()
⑤ .doOnCancel(() -> println("Pulse cancelled"))
⑥ .doOnTerminate(() -> println("Pulse terminated"));
}
First, take a second to appreciate how having a functional programming background helps
a lot to find such library really appealing.
For the past few years the trend on the JVM has been to go more functional, which started
progressively with lambdas and other functional constructs such as Optional and Stream,
so this API should look kinda familiar.
- Every 2 seconds
- Send a heartbeat request to the coordinator
- “log” that a heart beat has happened
- when this stream of operations comes to an end, just turn it into a single “completion signal”
- “log” when this
Fluxhas been cancelled (somehow) - “log” that the heart is no longer pulsing, whatever may be the cause
If you’re familiar with the Optional or Stream API or better, with the Vavr library,
the only thing which may surprise you is this then() function call.
Other than that, we’re infinitely flatMap—ing over a stream of ever-increasing longs.
It’s nice and all, especially compared to the 40+ lines of the Java NIO implementation, and even compared to the 10-ish lines of the straightforward blocking implementation.
Sadly, there is a “but”. Two actually.
The learning curve of FP
If programming is a kind of roller coaster then functional programming is definitely one of the sections that’s got a few hills. I’m not going to include any code example in this section but bear with me.
Not everyone is keen on learning “functional programming” and its many concepts. Those who do usually come to like the way it makes managing state more conceivable, helps isolate side-effects, promotes composability, increases conciseness, boosts expressiveness and all the yada yada of “safety”.
I agree with all the above. Unfortunately, in the FP advocates community there are
also the ones who can’t help but flog about category theory to death. Have you ever
heard the joke that “A monad is just a monoid in the category of endofunctors”?
Fasten your seatbelt now, ‘cause that’s so 2010s.
Apparently 2020 wasn’t bad enough to some, so over the years we’ve had variations like “A Kleisli is just …", or “An Arrow is just …", and the latest to my knowledge: “It’s always traverse”.
Some will tell you that you don’t have to worry about all this theoretical knowledge, that you’re already using monads and such without even realizing it. On the other hand it’s like each time a concept becomes somewhat approachable (due to a sheer amount of SO questions and blog posts) and even “mainstream” after a year or two, some folks decide to dive deeper in search of more infantilizing meme material. Jeez!
"The Haskell Pyramid" by Patrick Mylund Nielsen
[Disclaimer on the use of the previous image]
Tackling the cognitive load of asynchrony by hiding it behind functional abstractions is one approach to solving the problem (not the only one as we’ll see), and if you start using a “reactive” library, you’re in for a serious ride.
The learning curve of Rx
As if “mastering” FP wasn’t enough, the learning curve of Rx itself is no sinecure either.
It took me a good year to know what I was doing with Project Reactor and some of its features still feel impenetrable. The vicious thing, I think, is the false impression of simplicity, the warm cosy feeling given by code samples like the one above.
If you’ve read about reactive streams/reactive programming you may have been warned about the steep learning curve. In fact, it’s actually staged, at least in my opinion. Meaning that after having climbed your way up the first plateau, you’ll know just enough to be dangerous.
.block() here? .subscribe(foo -> { [...] bar.subscribe(); }) there? Using .flatMap,
.flatMapSequential and .concatMap interchangeably? .publishOn or .subscribeOn?
Flatmap-ing over a Flux when really what you wanted was a Mono because the previous
step was supposed to race rather than yield all values, and the type system didn’t save
ya (true story)?
Let’s remind ourselves what the logic looked like in Part 2 - Blocking code:
private Connection.Available getConnection()
throws EtaExceededException, InterruptedException
{
① return getConnection(0, 0, null);
}
private Connection.Available getConnection(long eta, long wait, String token)
throws EtaExceededException, InterruptedException
{
for(;;) {
if (eta > MAX_ETA_MS) {
throw new EtaExceededException();
}
if (wait > 0) {
Thread.sleep(wait);
}
println("Retrying download after " + wait + "ms wait.");
② Connection c = coordinator.requestConnection(token);
if (c instanceof Connection.Available) {
④ return (Connection.Available) c;
}
③ Connection.Unavailable unavail = (Connection.Unavailable) c;
eta = unavail.getEta();
wait = unavail.getWait();
token = unavail.getToken();
}
}
- We start with initial
etaandwaittimes at zero and no token (null). - We try to get a grant from the coordinator.
- If the coordinator rejects us with an
Unavailableresponse, we update the eta, wait and token and loop; - Otherwise we can return the
Availableresponse.
Ready to see what it looks like with a reactive streams implementation?
(You can find the complete source code for this sample here.)
private Mono<Connection.Available> getConnection() {
① return getConnection(0, 0, null);
}
private Mono<Connection.Available> getConnection(long eta, long wait, String token) {
AtomicLong etaRef = new AtomicLong(eta);
AtomicLong waitRef = new AtomicLong(wait);
AtomicReference<String> tokenRef = new AtomicReference<>(token);
return Mono.defer(() -> {
if (etaRef.get() > MAX_ETA_MS) {
return Mono.error(new EtaExceededException());
}
return Mono.delay(Duration.ofMillis(waitRef.get()))
② .flatMap(i -> coordinator.requestConnection(tokenRef.get()));
}).flatMap(c -> {
if (c instanceof Connection.Available) {
④ return Mono.just((Connection.Available) c);
} else {
Connection.Unavailable unavail = (Connection.Unavailable) c;
etaRef.set(unavail.getEta());
waitRef.set(unavail.getWait());
tokenRef.set(unavail.getToken());
③ return Mono.empty();
}
}).repeatWhenEmpty(Repeat
.onlyIf(ctx -> true)
.doOnRepeat(ctx ->
println(waitRef.get() + ", " + etaRef.get() + ", " + tokenRef.get())));
}

I have made two image to highlight the most relevant parts of the previous code, to give visual cues :


On the left, essential complexity, the job to be done aka attempt to retrieve a token.
On the right, accidental complexity, what Reactor requires in order to do the task.
The Mono.defer, the Mono.empty+repeatWhenEmpty, the two AtomicLong and the
AtomcReference are all necessary in order to implement an efficient, non-blocking
and stack-safe version of this very simple task.
I can’t stress enough how puzzling some other tasks can seem when working with such paradigm. On a daily basis there are:
- thread pools to handle, keep track of,
publishOnorsubscribeOn - blocking calls to avoid
- asynchronous calls and libraries to wrap
Futures to complete- backpressure to operate
InputStreamsto read from/write into and convert toFluxwithout blocking- local state to encapsulate in thread-safe ways
- context to make flow
- streams to
materialize/dematerialize - concurrency and parallelism amounts to consider (for many Rx operators!)
- queue sizes and defaults to take into account
- and a shit ton of marble diagrams to decypher…
Don’t believe me? Go watch this talk: Tomasz Nurkiewicz — Reactive programming lessons learned
Don’t believe him? Go ahead and try to implement a reactive semaphore…
This is something you learn from experience. And here’s my love-hate relationship
with reactive streams exposed: I kinda like this complexity. It is very satisfying!
Having to think about the problems, cracking the API, finding an “elegant” solution,
and it’s efficient!
The hard truth is, not many projects really need to trade computing costs for more expensive developers and, implicitly, higher maintenance costs.
Profiling
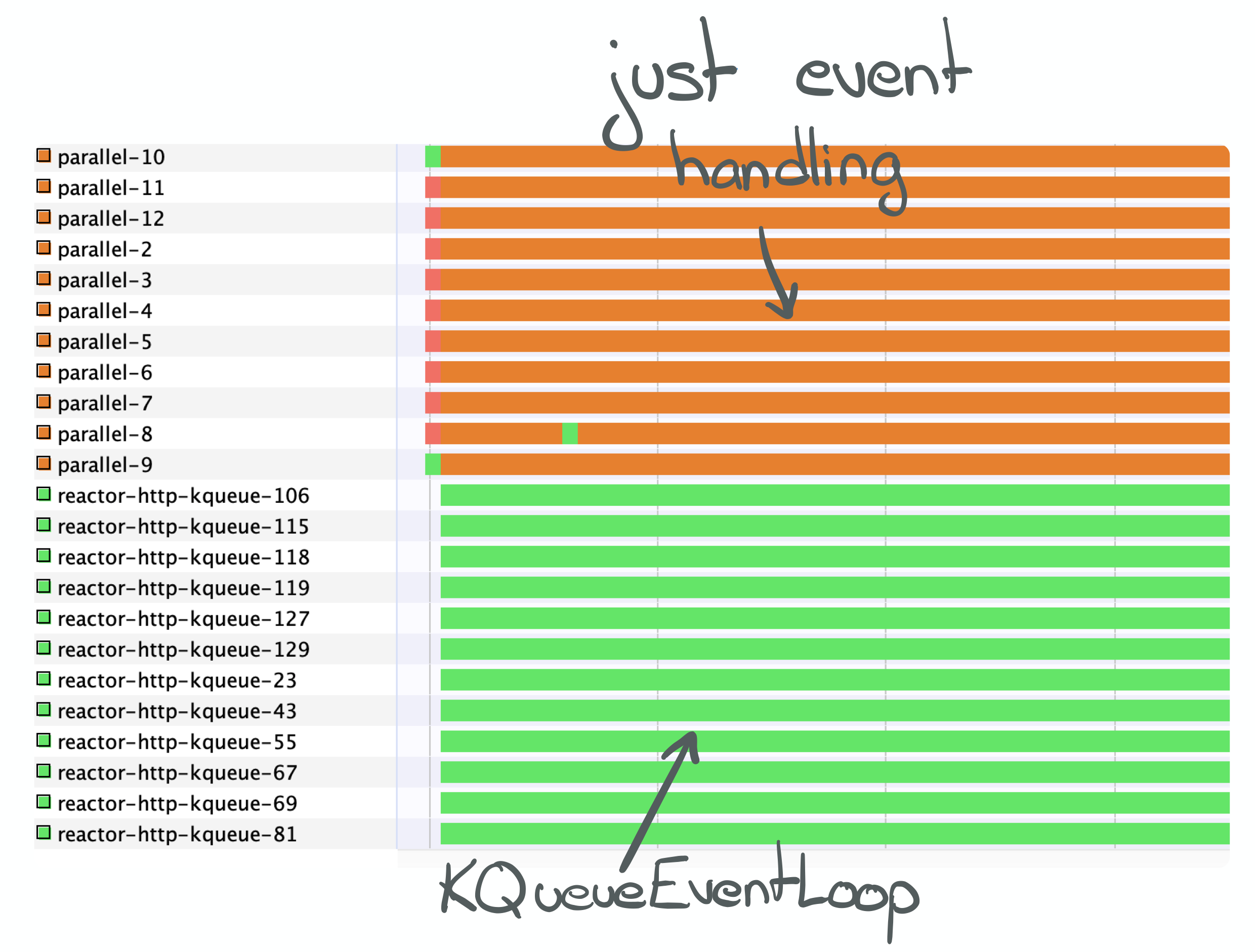
Once again, VisualVM confirms that we are, indeed, using our resources very efficiently.
Keeping aside the numbers used as suffixes of the reactor-http-kqueue-(n) threads
(which are irrelevant in this case), we see that there are only 12 of them living for the
whole duration of the experiment.
On the other side, a few more threads have been created implicitly by my implementation and are started “at subscription time” in order to deal with our application logic’s event handling.
Indeed, just like in the previous post, the threads of this pool spend most
of their time parked. The small amount of events to handle reactor calls (request,
next, etc) and logic is far from sufficient to keep them busy.
reactor-netty’s threads are seemingly 100% busy handling file descriptor events from the
kqueue syscalls (kqueue is the FreeBSD (OS X) equivalent to epoll that we have
talked about before), but this is a limitation from VisualVM. The load of concurrent
clients of this experiment is waaaaaay too small to actually make the threads as busy as
the monitoring tool seems to think and the threads are actually expecting events.
The CPU usage on my machine is, indeed, very small.
Conclusion
It took me a whole lot of time to get back on track with this series. The pandemic first, then life itself, took me away from it. I hope you’ll find this post useful, it’s not as technical as the previous ones because the Reactive Streams specification and various implementations are well established now, more than five years after the start of this series.
The main point of this article is to outline the accidental complexity that libraries like Reactor introduce, and how pervasive they are if you want to tap into its full potential end-to-end. I didn’t talk about backpressure yet, I plan to write a full article on this topic, which will require more code samples to try to explain correctly.
In the next articles of this series, we will (finally!) discover Loom, why it was brought into existence, what promises it made and how it kept its promises, how it works and how to use it. Stay tuned!
This blog uses Hypothesis for public and private (group) comments.
You can annotate or highlight words or paragraphs directly by selecting the text!
If you want to leave a general comment or read what others have to say, please use the collapsible panel on the right of this page.