December 23, 2019 — 14 minutes read
java concurrency
Part 3 in a series of articles about Project Loom.
In this part we re-implement our proxy service with an asynchronous API.The companion code repository is at arnaudbos/untangled
If you’d like you could head over to
Part 0 - Rationale
Part 1 - It’s all about Scheduling
Part 2 - Blocking code
Part 3 - Asynchronous code (this page)
Part 4 - Non-thread-blocking async I/O
Part 5 - Reactive Streams

Atelier de couture
J. Trayer 1854 CC0 1.0
Table Of Contents
We’ve covered a lot of ground in the previous entries and we concluded that blocking code “is bad” ©.
But what can we do about it?
While researching, I’ve read many blog posts presenting asynchronous programming
as a solution. It makes sense: our kernels use preemptive scheduling. So there’s nothing to do when the scheduler
time-slices a long-running thread. But we can maximize efficiency! By being
careful to avoid blocking calls and use asynchronous APIs.
We will write code that, instead of blocking, will call an async API. This call will return the control of execution immediately (so we can execute other instructions) and only notify us when the result is ready.
Let’s take a look at the second implementation I’ve made of the proxy service I’ve presented in the previous entry.
You can find the complete source code for this sample here.
Async API
Changing an API from synchronous to asynchronous seems simple at first.
From the inner out, we create a new function, asyncRequest, as an asynchronous alternative to
blockingRequest.
public void asyncRequest(ExecutorService, String, String, CompletionHandler)
asyncRequest has to return immediately to not block the calling thread, so we give it an
ExecutorService. This also benefits us, by being explicit about which pool is used.
It also takes a String for the URL, another for the headers, and also a CompletionHandler.
CompletionHandler is an interface one has to implement. Its methods are called by asyncRequest
once the result of the request is available: one callback in case of success, another in case of error.
public interface CompletionHandler<V> {
void completed(V result);
void failed(Throwable t);
}
I’ll spare you the request details hidden inside the intermediary
CoordinatorService#requestConnection(String, CompletionHandler, ExecutorService). Instead, let’s get to the new version
of getConnection we’ve talked about in the previous entry:
private void getConnection(CompletionHandler<Connection.Available> handler) {
getConnection(0, 0, null, handler);
}
private void getConnection(long eta,
long wait,
String token,
CompletionHandler<Connection.Available> handler)
{
if (eta > MAX_ETA_MS) {
if (handler!=null) handler.failed(new EtaExceededException());
}
boundedServiceExecutor.schedule(() -> {
println("Retrying download after " + wait + "ms wait.");
coordinator.requestConnection(
token,
new CompletionHandler<>() {
// ... We'll see this later
},
boundedServiceExecutor);
}, wait, TimeUnit.MILLISECONDS);
}
The signatures are like the synchronous ones, except for the extra CompletionHandler<Connection.Available>
handler.
But instead of making the request, we schedule it to the boundedServiceExecutor.
boundedServiceExecutor is an instance of ScheduledThreadPoolExecutor.
boundedRequestsExecutor =
Executors.newScheduledThreadPool(10, new PrefixedThreadFactory("requests"));
In fact, boundedServiceExecutor is not the only thread pool used in this implementation.
To make things explicit about where each task runs, I’ve created 3 dedicated executors:
// One from which service methods are called and coordinator requests are sent
boundedServiceExecutor =
Executors.newScheduledThreadPool(10, new PrefixedThreadFactory("service"));
// One from which gateway (download) requests are sent
boundedRequestsExecutor =
Executors.newScheduledThreadPool(10, new PrefixedThreadFactory("requests"));
// One from which heartbeat resquests are scheduled
boundedPulseExecutor =
Executors.newScheduledThreadPool(10, new PrefixedThreadFactory("pulse"));
Note that both
boundedServiceExecutorandboundedRequestsExecutorcould have been instances ofThreadPoolExecutor(usingExecutors#newFixedThreadPool(int, ThreadFactory))
rather thanScheduledThreadPoolExecutor;
because only heartbeat requests (usingboundedPulseExecutor) must be delayed.
But both being fix-sized pools, the result is the same.
Like the synchronous example, getConnection deals with the retry logic. But
CoordinatorService#requestConnection is asynchronous and takes a CompletionHandler, because it calls to
asyncRequest. So we have to implement both success and error callback methods.
new CompletionHandler<>() {
@Override
public void completed(Connection c) {
if (c instanceof Connection.Available) {
if (handler!=null)
① handler.completed((Connection.Available) c);
} else {
② Connection.Unavailable unavail = (Connection.Unavailable) c;
getConnection(
unavail.getEta(),
unavail.getWait(),
unavail.getToken(),
handler);
}
}
@Override
③ public void failed(Throwable t) {
if (handler!=null) handler.failed(t);
}
}
- In case of
Available, we’re done; we can complete the completion handler passed togetConnection. Its caller can be notified of the success and proceed (with the download). - In case of
Unavailable, we hide the retry logic and reschedule the call to requestConnection to the executor by recursively callinggetConnectionwith updated parameters. - In case of failure we simply propagate the error to
getConnection's caller.
The callbacks already make this logic cluttered enough; but we’re not done! We must now implement getThingy, our
service method which calls to getConnection and then start the download request.
private void getThingy(int i, CompletionHandler<Void> handler) {
println("Start getThingy.");
① getConnection(new CompletionHandler<>() {
@Override
② public void completed(Connection.Available conn) {
println("Got token, " + conn.getToken());
CompletableFuture<Void> downloadFut = new CompletableFuture<>();
③ gateway.downloadThingy(new CompletionHandler<>() {
@Override
④ public void completed(InputStream content) {
// Download started
}
@Override
⑥ public void failed(Throwable t) { ... }
⑤ }, boundedServiceExecutor);
}
@Override
⑥ public void failed(Throwable t) { ... }
});
}
- We’ve seen above that
getConnectiontakes a completion handler. - Its
completemethod will be called when we successfully get a download authorization from the coordinator. - On successful completion, the download starts, which materializes by calling
gateway.downloadThingy.downloadThingyis, itself, asynchronous because it also calls down toasyncRequest, so we must give it a new CompletionHandler. - This completion handler is passed an
InputStreamonce we connect to the data source. We can then read the content and forward it to this service’s client. The consumption of the InputStream and forwarding to the client is omitted for now and replaced by the “Download started” comment. downloadThingy's last parameter is an optional executor, used to specify which pool is used to run the completion handler. If omitted, it is the calling thread, but in this case, we specify that we want the content consumption/forwarding to happen on theboundedServiceExecutor.- In case of failure from
getConnectionordownloadThingy, we completegetThingy's completion handler with a failure.
Now that we have the structure, we can handle the content, but also start the periodic heartbeat requests!
Runnable pulse = new PulseRunnable(i, downloadFut, conn);
int total = 0;
① try(content) {
println(i + " :: Starting pulse ");
② boundedPulseExecutor.schedule(pulse, 2_000L, TimeUnit.MILLISECONDS);
// Get read=-1 quickly and not all content
// because of HTTP 1.1 but really don't care
byte[] buffer = new byte[8192];
③ while(true) {
int read = content.read(buffer);
// drop it
if (read==-1 || (total+=read)>=MAX_SIZE) break;
}
println("Download finished");
if (handler!=null)
④ handler.completed(null);
} catch (IOException e) {
err("Download failed.");
if (handler!=null)
④ handler.failed(e);
} finally {
⑤ downloadFut.complete(null);
}
Remember this code executes inside downloadThingy's completion handler, so when this code runs, the connection
to the data source is established.
- We encapsulate the logic inside a
try-with-resourceblock aroundcontent(the InputStream) because it can fail at any moment. - We’ve initialized a
PulseRunnable, which we can now schedule to send heartbeat requests. It will reschedule itself upon completion. The reference to the FuturedownloadFutallows to stop sending heartbeats when the download ends. We’ll seePulseRunnablelater. - In the mean time, we consume the InputStream and just ignore the content once again (not important).
- Finally, when the download stops, on success or on error, we complete
getThingy's handler accordingly. - We don’t forget to complete
downloadFuteither, so the heartbeats stop.
Almost done. We now look at PulseRunnable:
class PulseRunnable implements Runnable {
private int i;
private Future<Void> download;
private Connection.Available conn;
PulseRunnable(int i, Future<Void> download, Connection.Available conn) {
this.i = i;
this.download = download;
this.conn = conn;
}
@Override
public void run() {
if (!download.isDone()) {
println(i + " :: Pulse!");
① coordinator.heartbeat(
conn.getToken(),
new CompletionHandler<>() {
...
},
boundedPulseExecutor
);
} else {
println(i + " :: Pulse stopped.");
}
}
}
- When started, the runnable calls the asynchronous
CoordinatorService#heartbeatmethod with the token, completion handler and executor. The executor is responsible to run the handler’s methods (boundedServiceExecutorin this case, like when callingGatewayService#downloadThingyabove).
coordinator.heartbeat( // See previous snippet
conn.getToken(),
new CompletionHandler<>() {
@Override
② public void completed(Connection result) {
③ rePulseIfNotDone();
}
@Override
② public void failed(Throwable t) {
③ rePulseIfNotDone();
}
},
boundedPulseExecutor
);
- We ignore heartbeat results, whether successes or failures,
- And schedule a new heartbeat request as long as the download Future is not "done".
[Show the code for rePulseIfNotDone.]
Finally, the last piece of the puzzle: clients calling the service:
CompletableFuture<Void>[] futures = new CompletableFuture[MAX_CLIENTS];
for(int i=0; i<MAX_CLIENTS; i++) {
int finalI = i;
futures[i] = new CompletableFuture<>();
getThingy(finalI, new CompletionHandler<>() {
@Override
public void completed(Void result) {
futures[finalI].complete(result);
}
@Override
public void failed(Throwable t) {
futures[finalI].completeExceptionally(t);
}
});
}
Phew…
That certainly wasn’t easy code. Not like the synchronous code we’ve seen in the previous entry! The problem is still simple though, so it tells a lot about asynchronous programming: it’s a massive pain in the butt.
The logic is all over the place! Asynchronous APIs forces us to split our logic into pieces, but not the pieces we’d
like. A perfectly self-contained function in synchronous programming would have to be split into two to three (if not more)
callbacks and suddenly it’s not easy to reason about the code anymore.
This problem has a name: Callback Hell (and no, it’s not just JavaScript, I mean just look at the code above).
Profiling
If async is the answer to write efficient services that make the most out of server resources, maybe it’s worth the pain!
Profiling this code revealed that CPU usage was still low, more or less like in the previous implementation. Threads are more interesting:
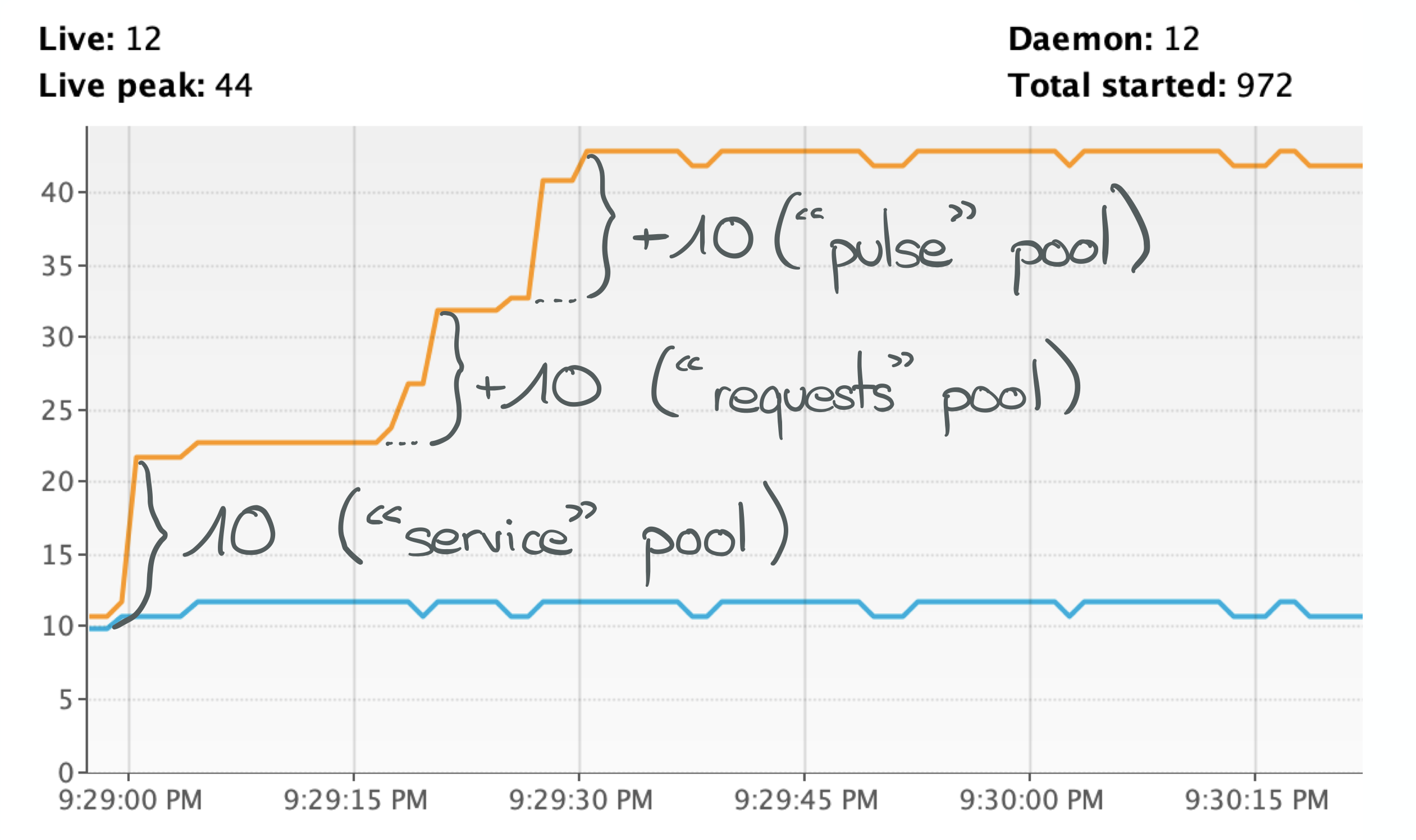
200 clients, 30 threads, everything is proceeding as I have foreseen. But wait… this is very slow!
This screenshot shows only the first minute of runtime and then the rest of the chart looks the same.
The previous implementation created a bunch of threads but at least finished quickly, in less than a minute.
Why is it so slow?
VisualVM to the rescue:
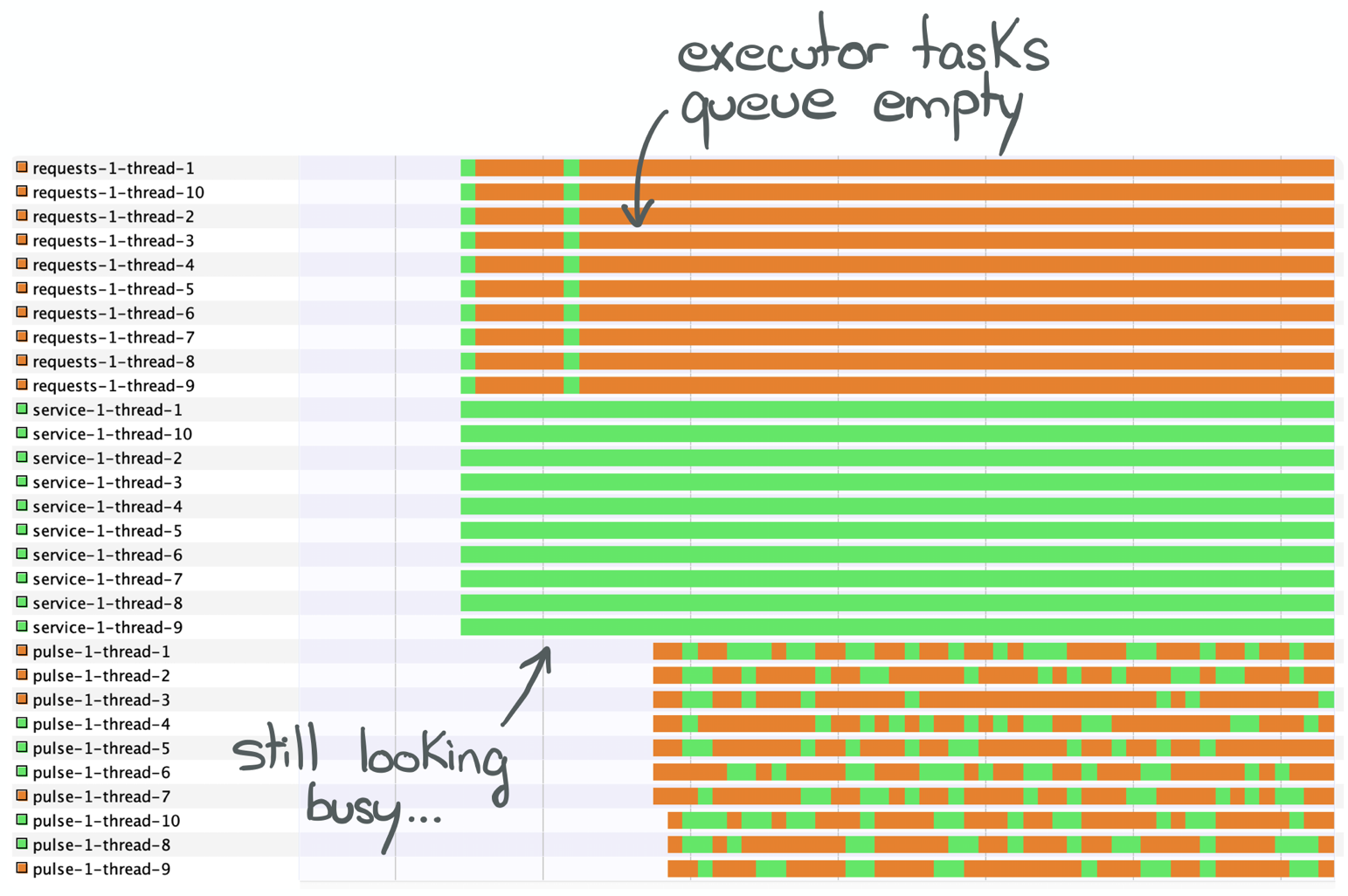
Let’s refer to the implementation to find what threads, from each thread pool (request, pulse and service)
is doing what.
Request threads
Threads whose names begin with request come from boundedRequestsExecutor. The only place where this Executor is
used is inside downloadThingy, which I had omitted before. Here it is:
class GatewayService {
void downloadThingy(CompletionHandler<InputStream> handler,
ExecutorService handlerExecutor)
{
① asyncRequest(
boundedRequestsExecutor,
"http://localhost:7000",
String.format(HEADERS_TEMPLATE, "GET", "download", "text/*", String.valueOf(0)),
new CompletionHandler<>() {
@Override
public void completed(InputStream result) {
if (handler != null)
if (handlerExecutor!=null) {
handlerExecutor.submit(
() -> handler.completed(result)
);
} else {
handler.completed(result);
}
}
@Override
public void failed(Throwable t) {
if (handler != null)
if (handlerExecutor!=null) {
handlerExecutor.submit(
() -> handler.failed(t)
);
} else {
handler.failed(t);
}
}
});
}
}
The code of asyncRequest is secret sauce for the moment, suffice to say that the executor it is given
(boundedRequestsExecutor in this case) serves only to call its submit(Runnable) method.
So the request-* threads in the VisualVM screenshot above are all doing the same thing: execute an asyncRequest
and pass the result to whoever the caller is.
Pulse threads
Threads whose names begin with pulse come from boundedPulseExecutor. The only places where this Executor is
used is when scheduling the heartbeat requests, from within getThingy and from the “pulse” Runnable itself:
boundedPulseExecutor.schedule(pulse, 2_000L, TimeUnit.MILLISECONDS);
It is also given as the last parameter to CoordinatorService#heartbeat to execute its completion
handler:
@Override
public void completed(InputStream is) {
Runnable r = () -> {
if (handler != null)
handler.completed(parseToken(() -> is));
};
if (handlerExecutor!=null) {
handlerExecutor.submit(r);
} else {
r.run();
}
}
So the pulse-* threads, in the VisualVM screenshot above, are doing small things too: execute a heartbeat
asyncRequest and a bit of parseToken, which consists in decoding a few bytes.
Service threads
Threads whose names begin with service come from boundedServiceExecutor and are used in several places.
- in
getConnection, to submit the call toCoordinatorService#requestConnection - to execute the completion handler of
CoordinatorService#requestConnection - to execute the completion handler of
GatewayService#downloadThingy - to execute the calls to
asyncRequestinsideCoordinatorService#requestConnectionandCoordinatorService#heartbeat
So the service-* threads in the VisualVM screenshot above are doing a few asynchronous calls and also a bit of
callback execution.
A word about ScheduledThreadPoolExecutor
It’s time to introduce the ScheduledThreadPoolExecutor.
Contrary to cached ThreadPoolExecutor, it doesn’t spawn new threads to keep up with the number of Runnable.
Instead, it stays with the number of threads it is passed when created.
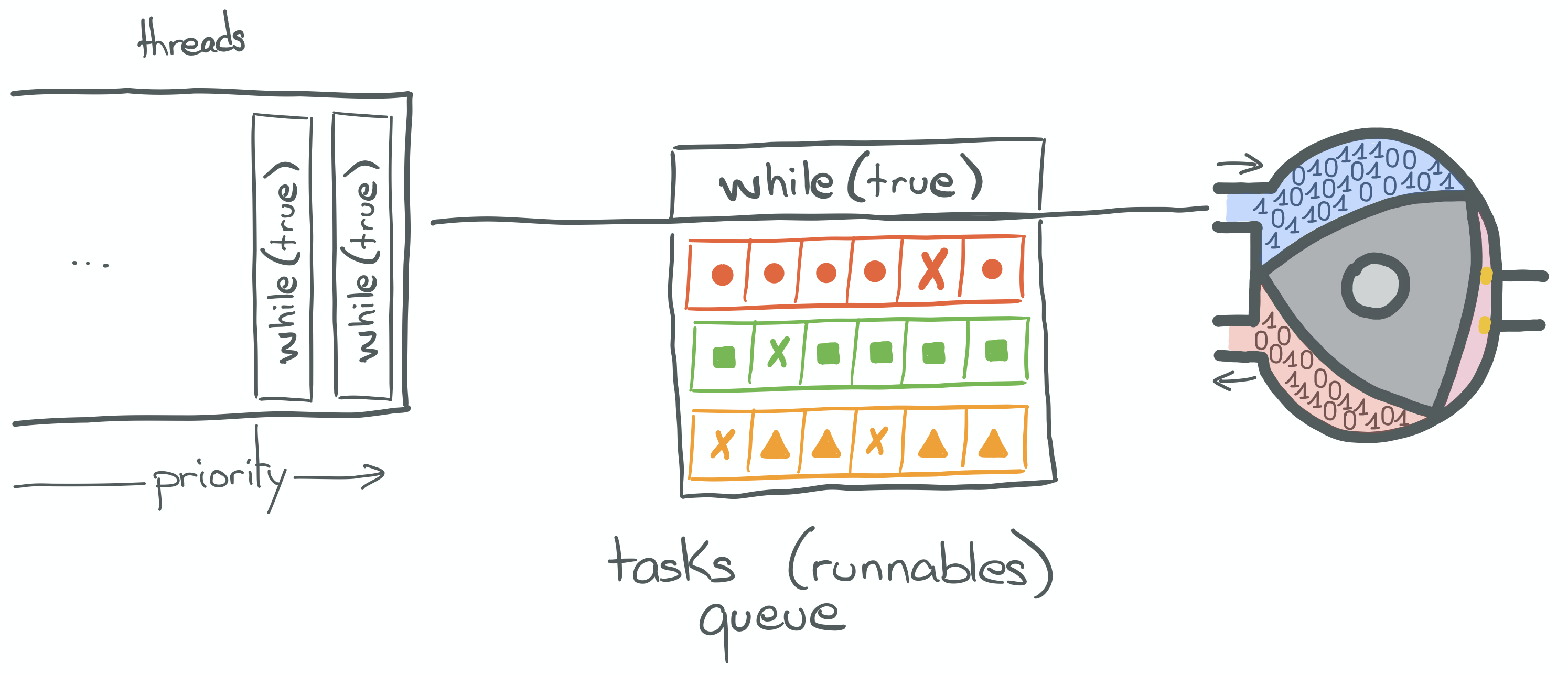
Each thread runs an infinite loop, executing Runnable after Runnable from the executor’s tasks queue. When using this kind of executor, the goal is to execute non-blocking calls. Blocking calls suspend the thread until the result of the call is available. Executing a blocking call on such thread would suspend it and prevent it from executing the next tasks from the queue!
As seen in Part 2, we want to avoid blocking calls. Especially with this kind of executor, because it becomes possible to bring the whole application to a halt!
Fortunately, our whole implementation is asynchronous! Every method of our service submits tasks to an executor and there are callbacks all over the place.
Beware of the lurking blocking call
We now have a bit more context on what each thread does. Let’s take another look at the VisualVM screenshot:
The request-* and pulse-* threads spend most of their time parked.
Each thread in those pools looks for tasks to execute (runnables) coming down the executor’s queue. Because the only tasks submitted to them are asynchronous, their execution are quick! Soon, the queue is drained and there’s nothing to do. The executor will thus park the threads.
The service-* threads, however, spend all their time running. And it is as weird as in the previous entry:
we’ve supposed to execute only asynchronous methods and compute nothing. I’ll spare you the thread dump, let’s
jump to the flame graph:

There’s a blocking call lurking in a dark corner of our “beautiful” asynchronous API!
And if you didn’t see it coming, maybe you understand why I didn’t show the code of asyncRequest before.
Let’s look:
public static void asyncRequest(ExecutorService executor,
String url,
String headers,
CompletionHandler<InputStream> handler)
{
executor.submit(() -> {
try {
InputStream is = blockingRequest(url, headers);
if (handler!=null)
handler.completed(is);
} catch (Exception e) {
if (handler!=null)
handler.failed(e);
}
});
}
"Mischief managed"
Under the hood, asyncRequest calls down to blockingRequest and its blocking SocketChannel/InputStream!
The reason why the service-* threads look busy is that they are actually blocked.
Previously, I’ve asked: “Why is it so slow?". The answer is: because those threads are from a pool managed by a
fixed-size ScheduledThreadPoolExecutor, on top of which no more than 10 simultaneous requests can be running.
The threads being blocked, they prevent other tasks submitted to the executor from running.
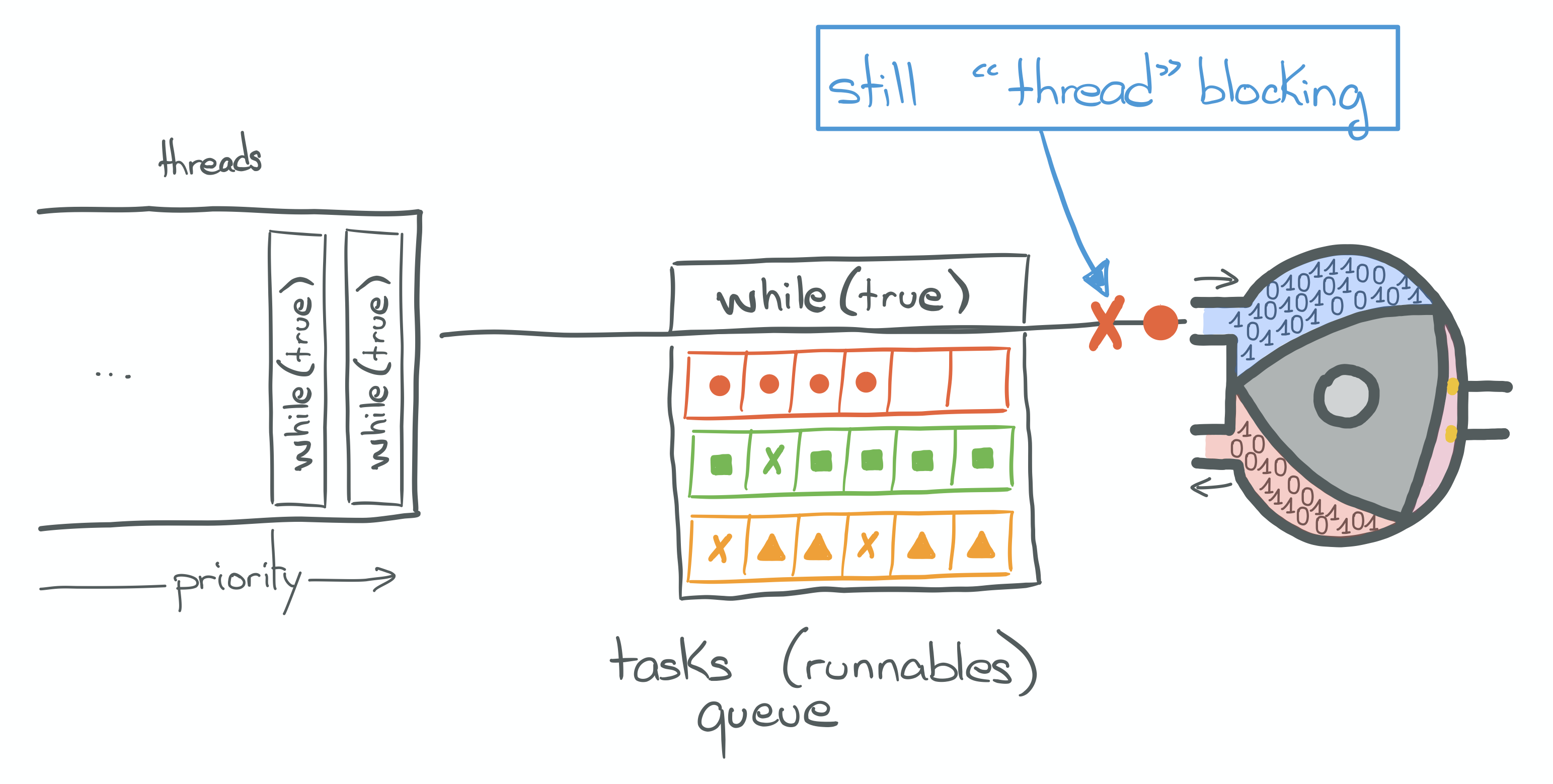
Thus, the net effect of changing this API from synchronous to asynchronous has been a latency increase. Because the jobs keep piling up in the executor’s queue! We’re, in effect, limited our parallelism.
Conclusion
Some blog posts present asynchronous programming as a solution to the problem of scaling a service. This bothers me.
They often use asynchronous in opposition to blocking. However, the opposite of blocking is non-blocking, not
asynchronous. Using non-blocking alone conflates not blocking the current thread with not blocking any thread.
Non-blocking does not equate non-thread-blocking !
As seen above, using an asynchronous API doesn’t mean anything about its thread-blocking properties.
An asynchronous call submitted to an executor doesn’t block the current thread, for sure, but it may very well block
the thread it is running on! This is usually where you read comments such as “use a dedicated thread pool”.
Indeed, you want to dedicate a thread pool for those blocking calls to avoid impacting the rest of your application.
But you’re left with two choices. Either use an unbounded thread pool, risking unpredictable behaviour, or use a bounded
one, risking increased latency for those tasks.
I prefer to think about blocking and non-blocking as runtime properties. Likewise, I much prefer using asynchronous as opposed to synchronous when talking about an API or programming style. Conflating sync/async as thread-blocking/non-thread-blocking is a source of confusion. In fact, both are orthogonal.
But there’s a reason why both are often mixed-up: today, the only—i.e. built-in— way to execute non-thread-blocking
code on the JVM is to use asynchronous API.
In the next part, we’ll re-implement asyncRequest to be truly non-blocking.
Post Scriptum
Writing asynchronous code is hard.
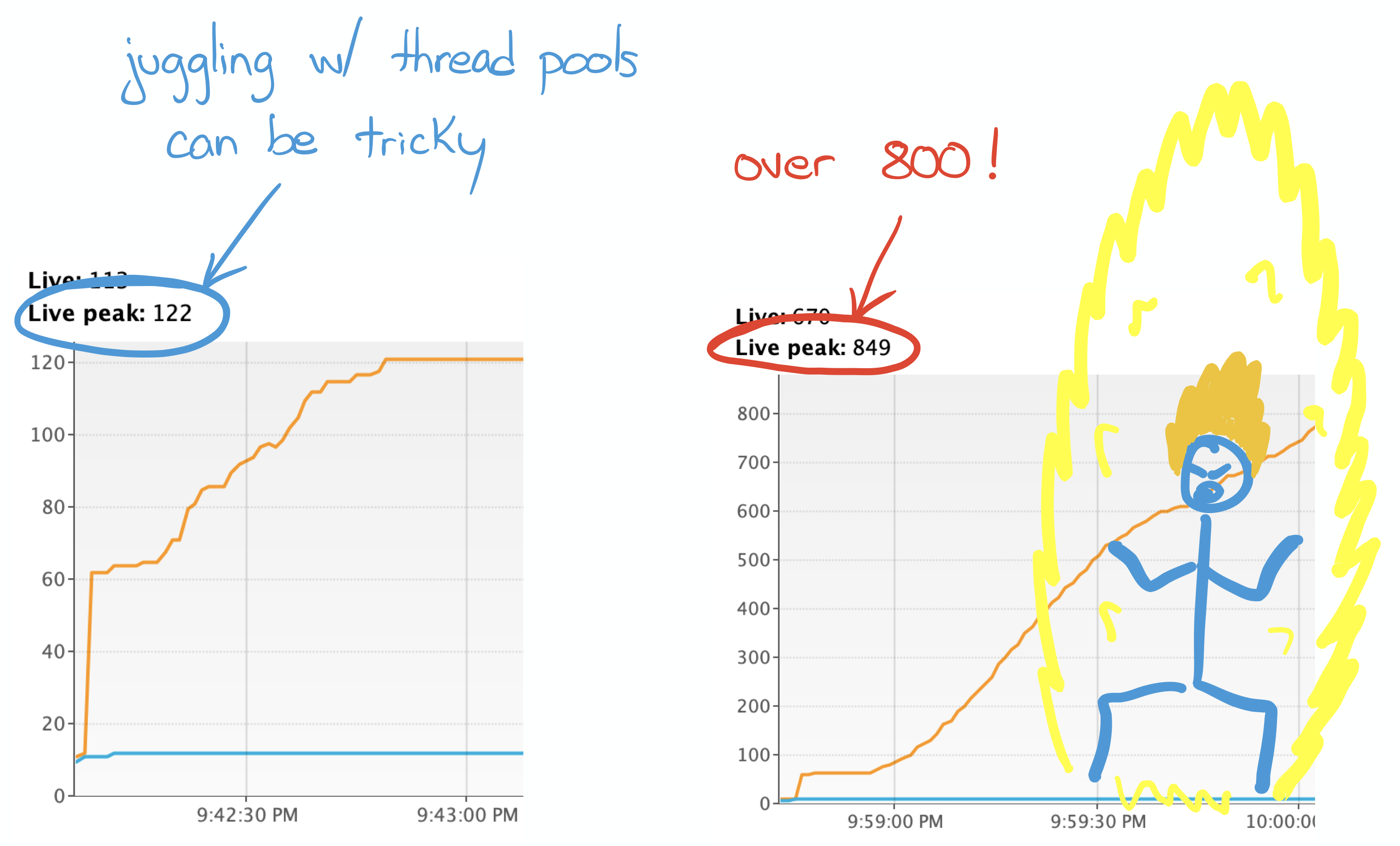
On the left a peak to 122 live threads when I did a small mistake. On the right a peak to more than 800 live threads when I messed up on purpose to see the result (I swear!).
This blog uses Hypothesis for public and private (group) comments.
You can annotate or highlight words or paragraphs directly by selecting the text!
If you want to leave a general comment or read what others have to say, please use the collapsible panel on the right of this page.